|
I am currently a Senior Machine learning Engineer at Apple, working on Generative Models. I graduated with a Master's degree from The Robotics Institute (MSR), Carnegie Mellon University in 2022. During my Master's, I was advised by Prof. Katerina Fragkiadaki and collaborated with Prof. Shubham Tulsiani. Before this, I was working at Media and Data Science Research Labs Adobe, India and had the opportunity to collaborate with Prof. Vineeth N Balasubramanian. I graduated from Indian Institute of Technology Kharagpur in Mathematics and Computing. My research interests are Computer vision, 3D generative models, adversarial machine learning, and few-shot learning. [Email] [LinkedIn] [Resume] [Google Scholar] |
 |
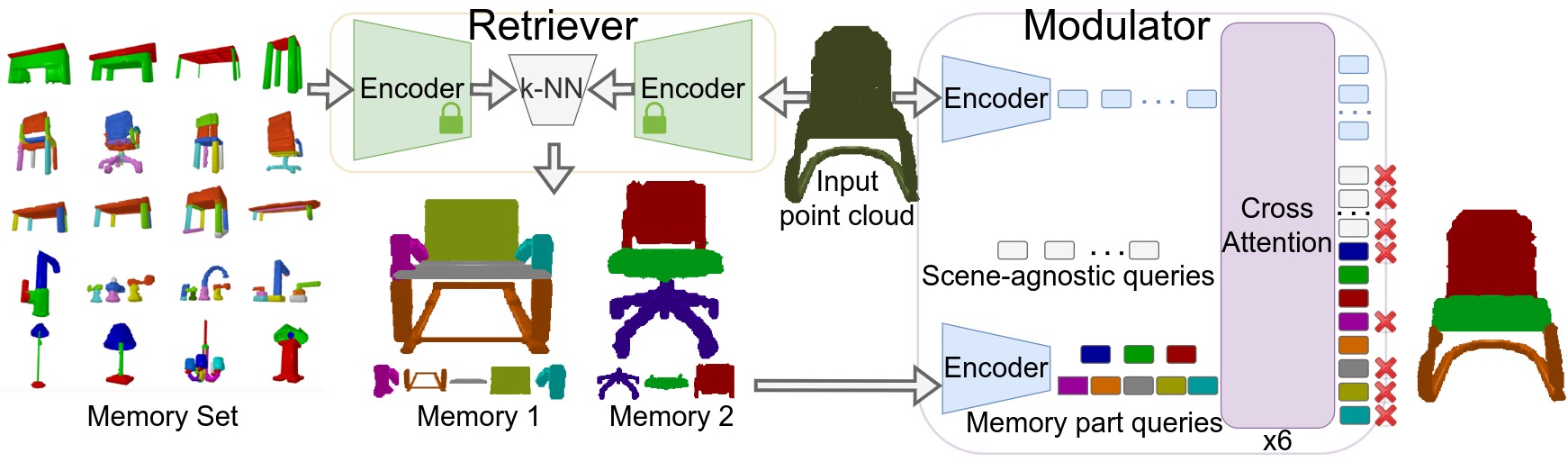
|
We present Analogical Networks, a model that casts fine-grained 3D visual parsing as analogy-forming inference: instead of mapping input scenes to part labels, which is hard to adapt in a few-shot manner to novel inputs, our model retrieves related scenes from memory and their corresponding part structures, and predicts analogous part structures in the input object 3D point cloud, via an end-to-end learnable modulation mechanism.
|
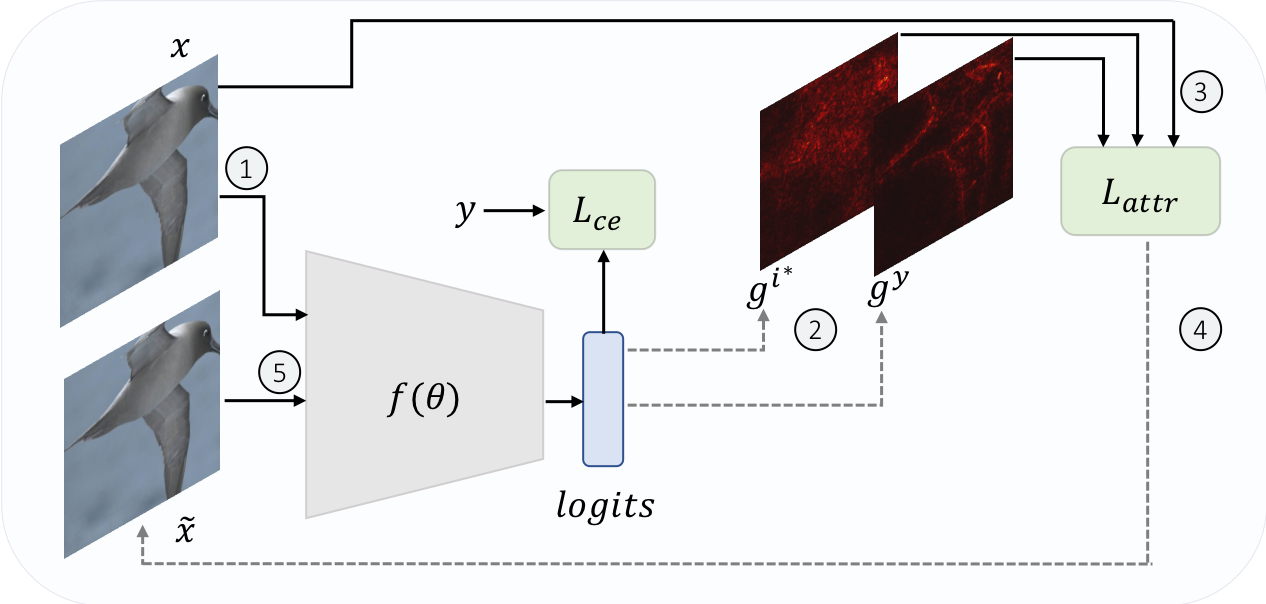
|
We propose a robust attribution training methodology ART that maximizes the alignment between the input and its attribution map. ART induces immunity to adversarial and common perturbations on standard vision datasets. It achieves state-of-the-art performance in weakly supervised object localization on CUB dataset.
|
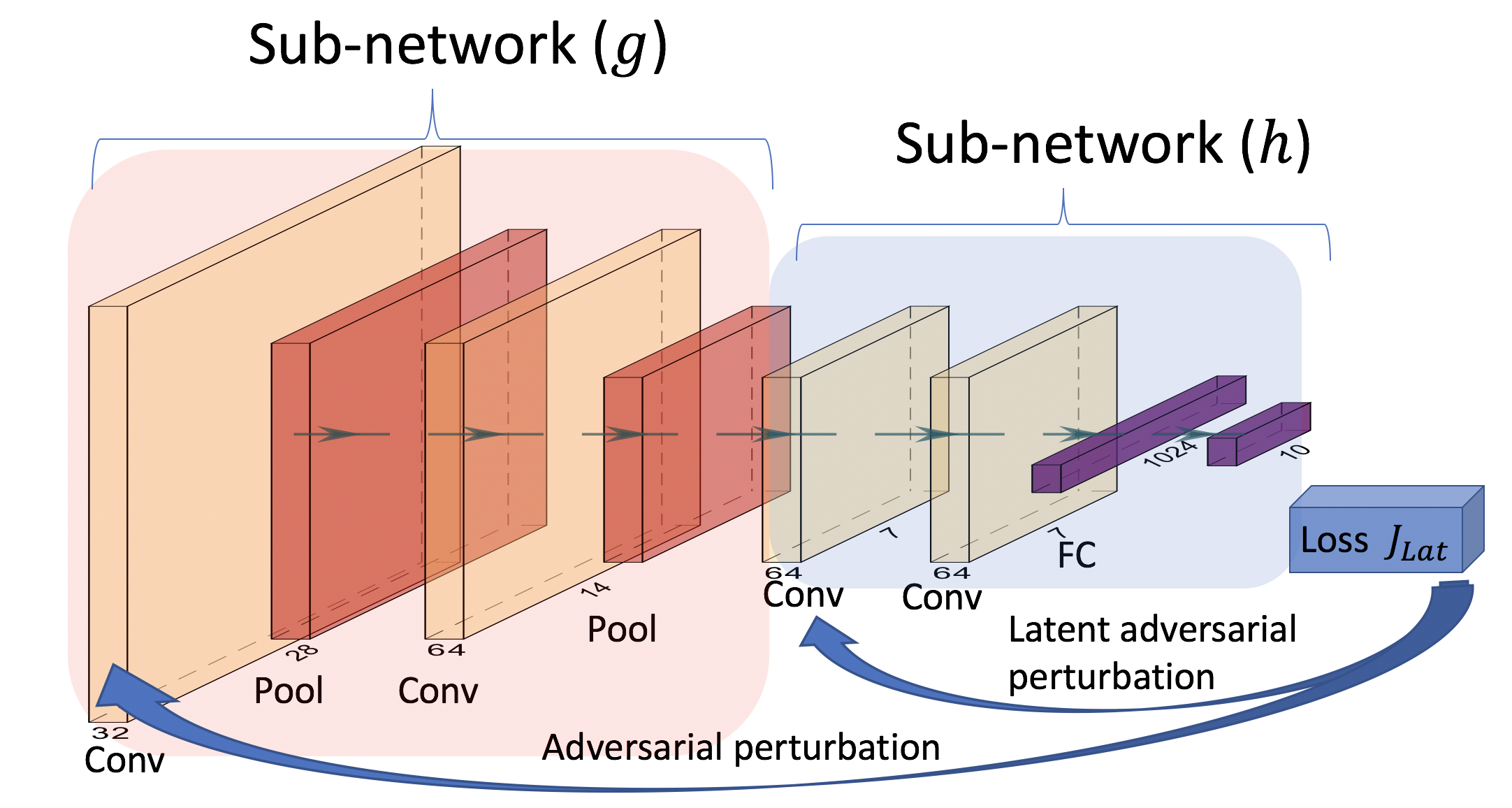
|
We Analyze the adversarial trained models for vulnerability against adversarial perturbations in the latent layers. The algorithm achieved the state-of-the art adversarial accuracy against strong adversarial attacks.
|
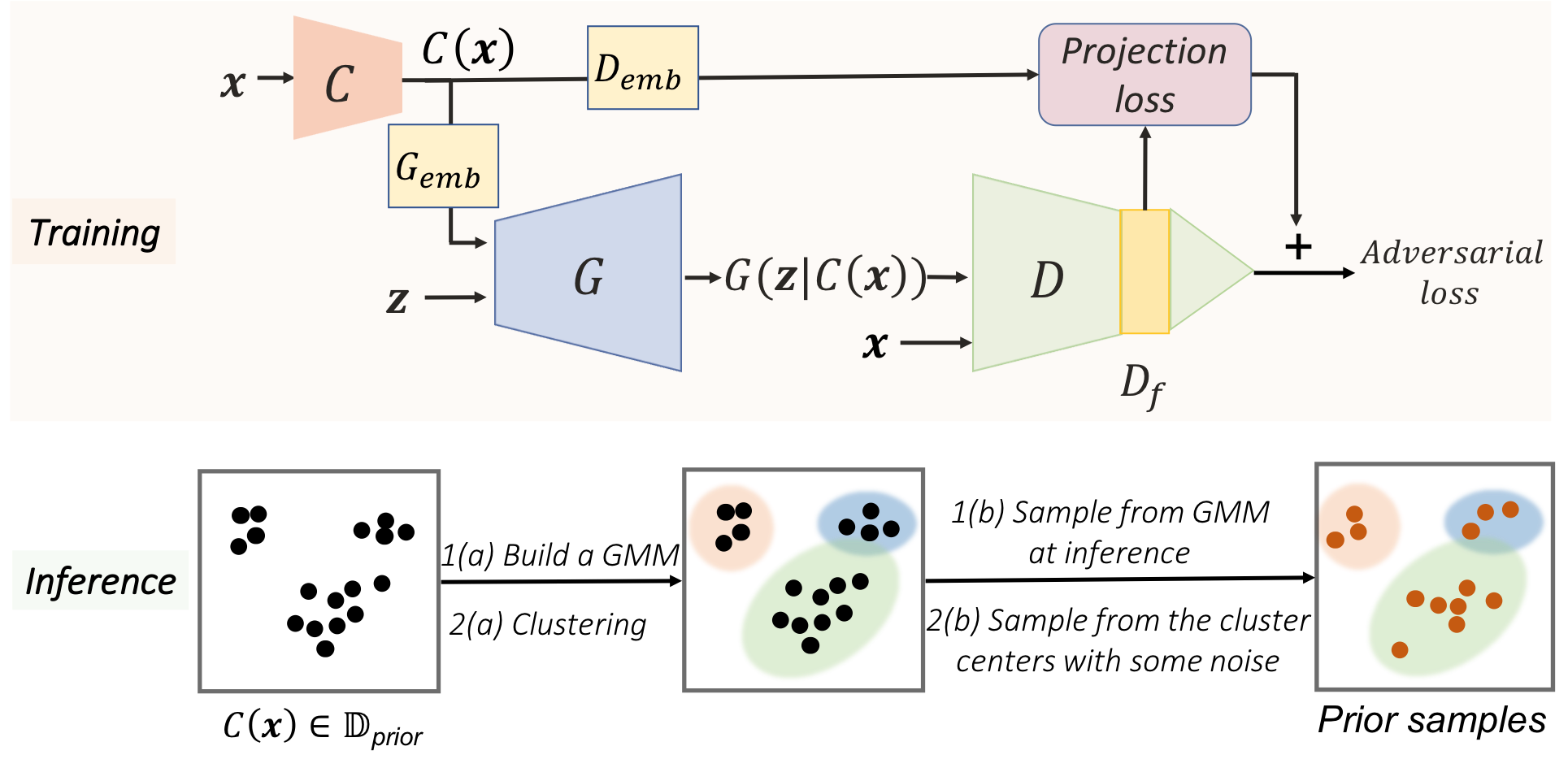
|
We propose a novel transfer learning technique for GANs in the limited data domain by leveraging informative data prior derived from self-supervised/supervised pretrained networks trained on a diverse source domain.
|
|
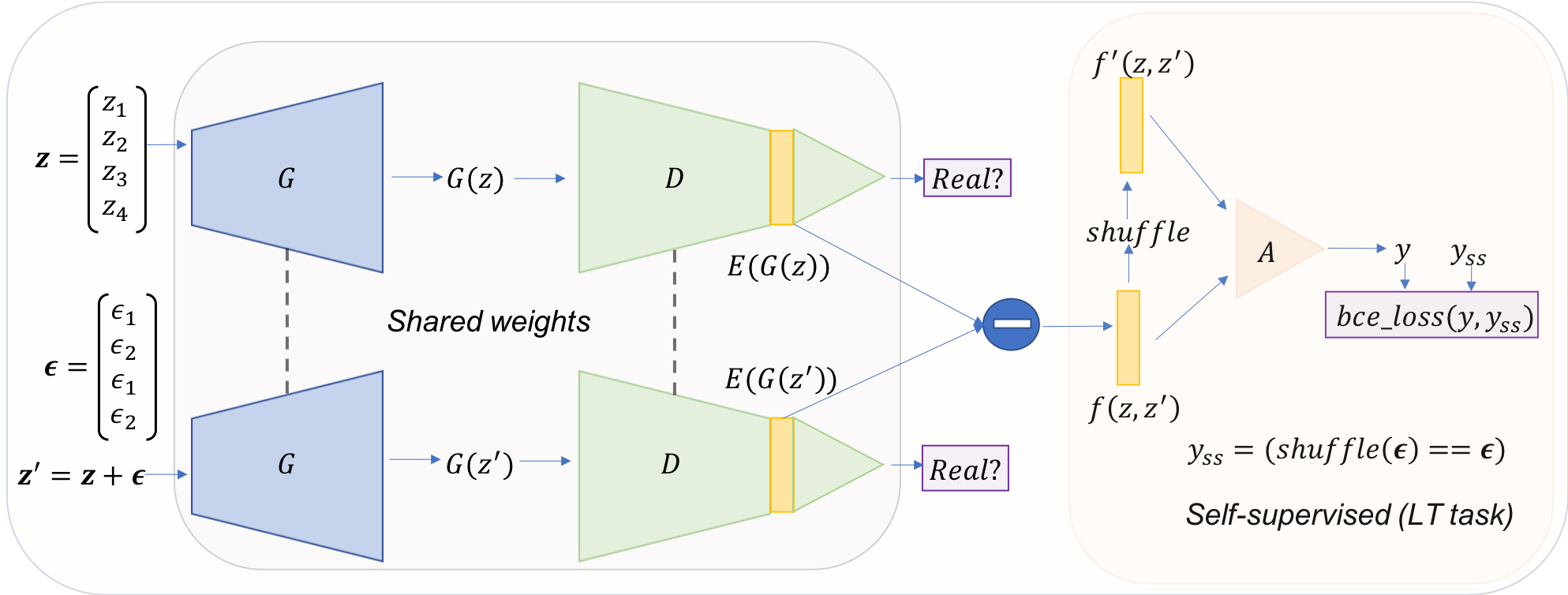
We propose a self-supervised approach (LT-GAN) to improve the generation quality and diversity of images by estimating the GAN-induced transformation (i.e. transformation induced in the generated images by perturbing the latent space of generator).
|
|
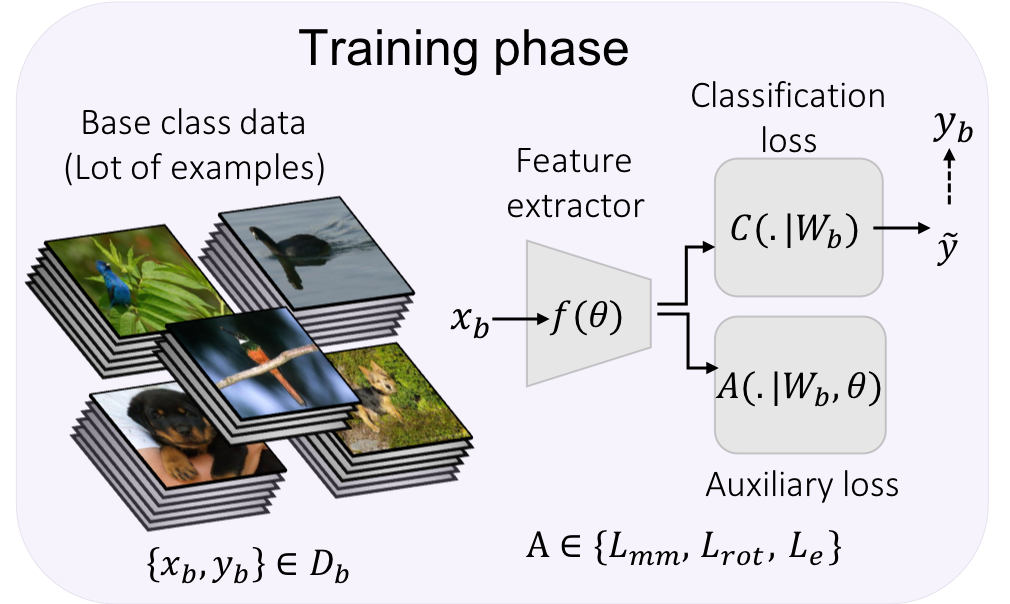
We Use self-supervision techniques like rotation prediction and exemplar, followed by manifold mixup for the few-shot classification tasks. The proposed approach beats the current state-of-the-art accuracy on mini-ImageNet, CUB and CIFAR-FS datasets by 3-8%.
|
|
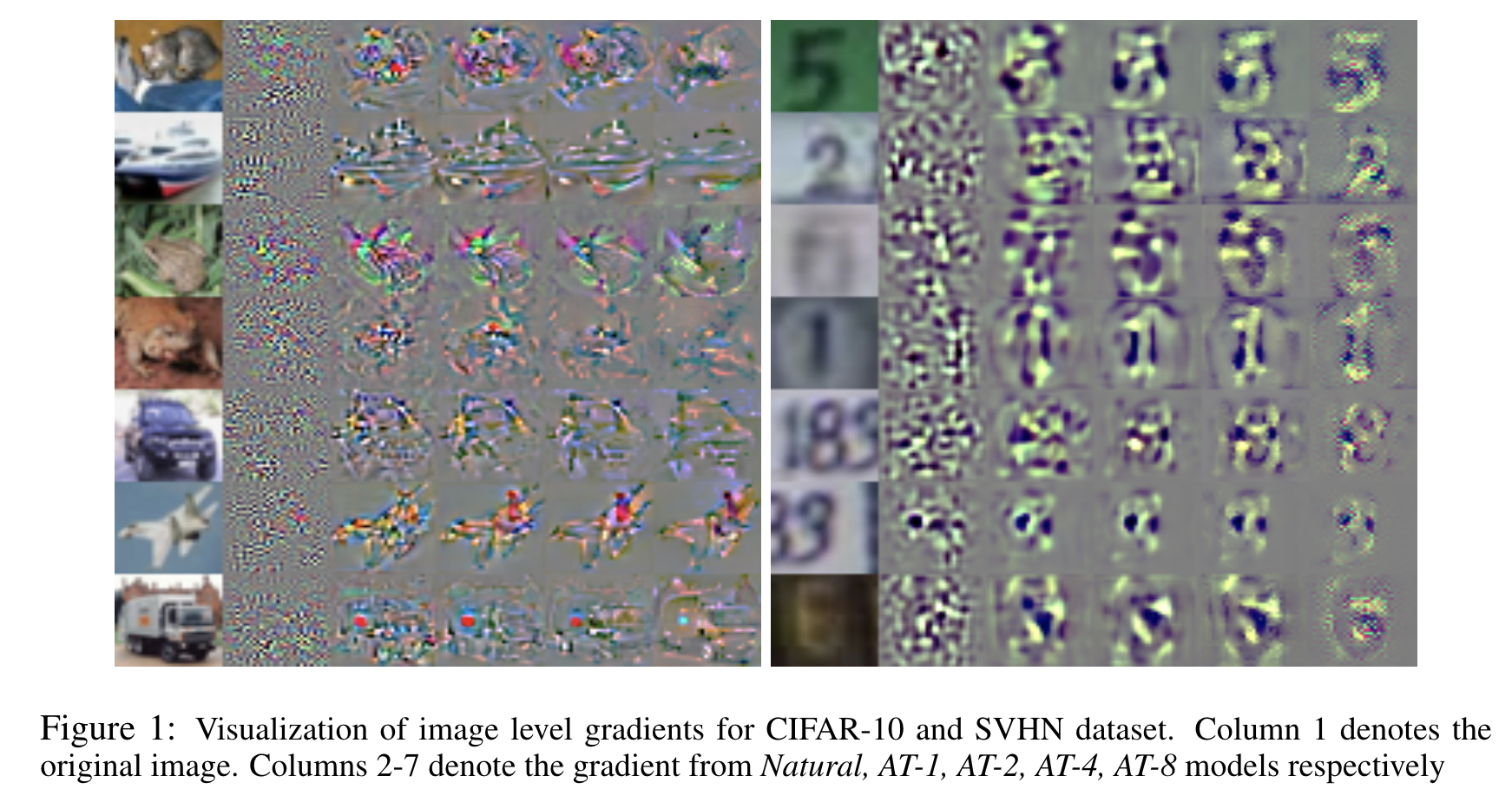
In this paper, we leverage models with interpretable perceptually-aligned features and show that adversarial training with low max-perturbation bound can improve the performance of models for zero-shot and weakly supervised localization tasks.
|
|
|